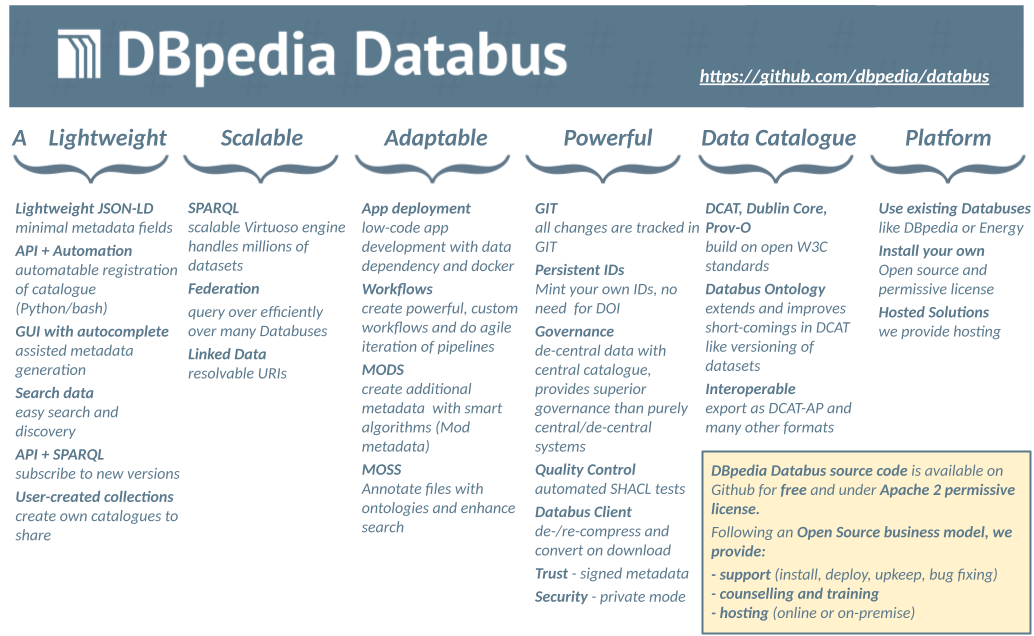
The DBpedia Databus is a data cataloging and versioning platform for data developers and consumers. The Databus lets you deploy your datasets in a well-structured way and eases the process of continuously improving your data. This has not only the potential to streamline your data releases but also makes new data releases retrievable by other users in a unified and automatable way.
Check out the DBpedia Databus NOW!![]()
Download via GitHub: https://github.com/dbpedia/databus
Improve Your Data
Creating good data is hard. The DBpedia knowledge graph has been under development for many years and is being improved to this day. Working on such a large scale dataset has often proven to be a messy and difficult process. The Databus made it possible to structure and streamline the DBpedia releases and shrink the release cycle from more than a year to a single month. Data is not only released more frequently but also in a clear and modular fashion for easier retrieval on the consumer side. Having passed the test for complex dataset structures such as DBpedia, the Databus enables you as well to build an automated DBpedia-style extraction, mapping and testing for any data you need.
Usage Scenario
A use case for the DBpedia Databus could be the cataloging and analysis of plants. Biologists create catalogs of plants with numerous different genera, describe them in detail and relate the genera to each other. The DBpedia Databus offers a suitable environment to version this work, to extend it and to make it easily accessible to others.
Suppose a biologist has already provided a catalog of the succulent plant family on the Databus. Another biologist who is interested in data on succulents for his work can then easily download the catalog. While exploring the data he notices that information about echeveria, a subfamily of succulents, is underrepresented in the dataset. For this case the Databus platform enables him to derive a new dataset from the original one, expand it and register it on the Databus as well.
Once deployed it is accessible for further work by other biologists. Due to the architecture of the DBpedia Databus, it can be clearly tracked how derived datasets were created and from which original dataset they were built.
Moreover, there might be data creators who are interested in specific parts of a dataset, e.g. only the echeveria data out of the catalog of the succulent plant family. The echeveria data can be retrieved by using the keyword search on the Databus and automated updates of the selected data are provided as soon as a new dataset version is released by the dataset provider.
The Databus and DBpedia Releases
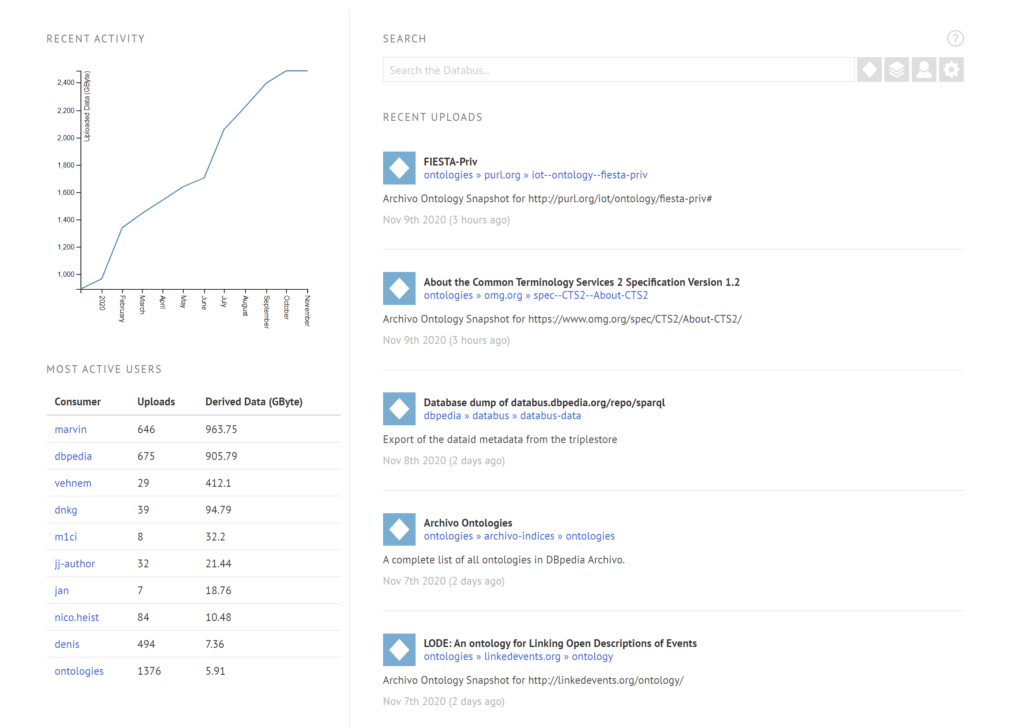
One of the big strengths of the Databus is the automation capability of data releases. This facilitates the release of new data versions and encourages a migration towards frequent and periodic releases. The Databus catalog provides a clear structure for this process and even makes it automatable so your monthly, weekly or even daily data releases can be run by a script.
DBpedia uses this feature to publish the latest DBpedia datasets as soon as they have been generated. DBpedia maintains a large distributed, open, and free infrastructure which is now almost completely powered by the Databus and includes:
- monthly, fully automated extractions from Wikipedia and Wikidata in an agile, cost-efficient manner producing around 5500 triples per second as well as 21 billion triples per release.
- metadata aggregation for 146,113 files as of Sep 19th, 2020.
Please note that the DBpedia release and the DBpedia Databus are two different things. While the first denotes the actual datasets, the latter refers to the publishing platform of the data.
Data Hosting and Retrieval
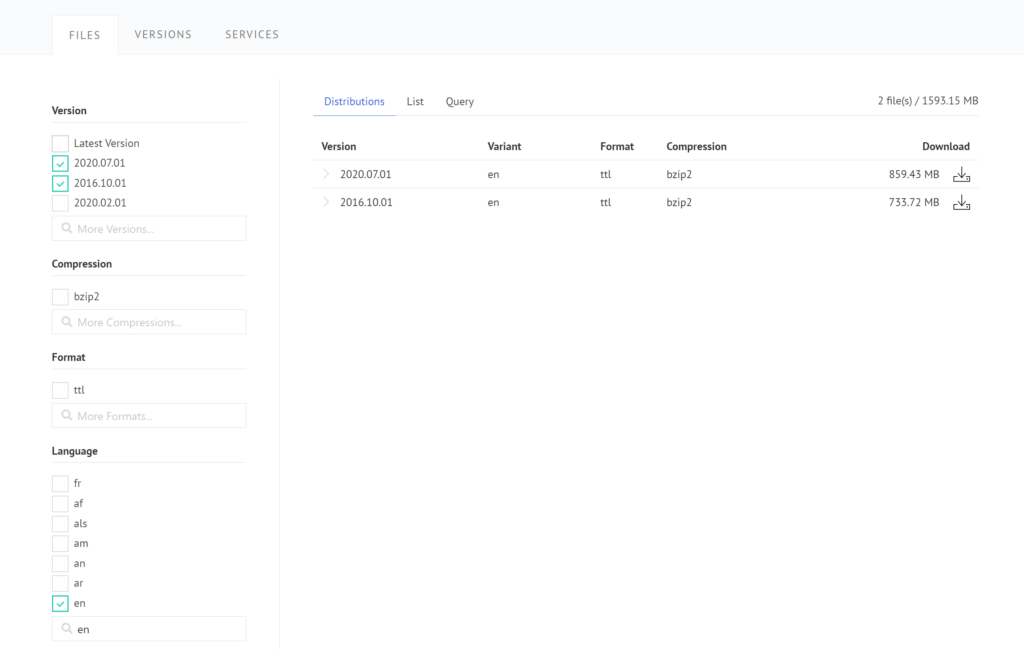
The DBpedia Databus is a metadata platform inspired by Maven where the data is made accessible, yet not hosted. In order to register data on the DBpedia Databus, data creators need to post a metadata file in the RDF format to the Databus SPARQL API. The data itself can be hosted anywhere as long as it is accessible via URL. Thus, data publishers maintain full control over their data.
The data publishing process is completely decoupled from the format, type or size of the data which enables users to upload not only RDF and Linked Data formats but data in any format.
If you like to publish data on the DBpedia Databus, feel free to call up the detailed instructions for publishing data here.
In order to get access to any published data on the Databus users can query the DBpedia Databus-related SPARQL endpoint or use the Databus search API.
Databus Collections
Databus Collections are another great tool for retrieving and managing data. Collections let you group multiple datasets into bundles for easier retrieval, organization and shareability. This feature is used for DBpedia to aggregate all the files of the latest DBpedia release under one single URL.
All RDF metadata uploaded to the Databus can be queried via the Databus SPARQL endpoint. Since the metadata also contains the download URLs of the actual files, any amount of desired download URLs can be selected by one or more SPARQL queries. Databus Collections make organizing, publishing and sharing of such download URL selections possible. A Databus Collection wraps a SPARQL query with additional metadata and can be retrieved or shared via URI.
You can create Databus Collections for your data on the Databus website. In order to specify your data selection, you can either write your own SPARQL query or use the provided Databus-centric query generator interface.
Architecture
In more technical terms, the DBpedia Databus is a centrally managed platform to register metadata of decentral storage and processing units, analogously to a data bus in computers. Its target is the migration from P2P to an efficient platform with lower entry barriers and improved discovery and cooperation for consumers while keeping consumers in control of their data. Users add storage in form of self-hosted HTTP-accessible files in any format and submit openly-licensed, interoperable and consistent RDF metadata (DCAT, DataID) to a central component that exposes a SPARQL API to query the metadata graph. The system is designed to achieve the following objectives:
- Provenance and trust: Data, metadata, and license statements are signed by the users via private key and verified on upload via .X509 certificates and WebID, thus, guaranteeing the automatic verifiability of the license and origin of all files.
- FAIR++: Databus fulfills and supersedes the default FAIR data principles. The main principles of findability, accessibility, interoperability, and reusability are implemented with state-of-the-art Semantic Web technology, fully automated and machine-actionable and -verifiable.
- Stable dataset identifiers: The conceptual model of the Databus distinguishes the abstract identity of a dataset from the individual versions (e.g. monthly snapshot).
- Stable collection identifiers: Consumers can create their own collections (DCAT catalogs) with stable IDs to allow persistent citations in research papers.
- High degree of automation: Programmatic access via query: 1. Locate files in the decentral storage units and 2. download. The Databus Client offers a conversion layer to convert common file formats and compression variants. A low-code approach enables the automatic deployment of data into applications via Docker (data-in-software paradigm). Inspired by Maven, GitHub, and the Debian package manager.
- Did you consider this information as helpful?
- Yep!Not quite ...