
We are pleased to announce immediate availability of a new edition of the free and publicly accessible SPARQL Query Service Endpoint and Linked Data Pages, for interacting with the new Snapshot Dataset.
News since DBpedia Snapshot 2021-09
+ Release notes are now maintained in the Databus Collection (2021-12)
+ Image and Abstract Extractor was improved
+ Work in progress: Smoothing the community issue reporting and fixing at Github
What is the “DBpedia Snapshot” Release?
Historically, this release has been associated with many names: “DBpedia Core”, “EN DBpedia”, and — most confusingly — just “DBpedia”. In fact, it is a combination of —
- EN Wikipedia data — A small, but very useful, subset (~ 1 Billion triples or 14%) of the whole DBpedia extraction using the DBpedia Information Extraction Framework (DIEF), comprising structured information extracted from the English Wikipedia plus some enrichments from other Wikipedia language editions, notably multilingual abstracts in ar, ca, cs, de, el, eo, es, eu, fr, ga, id, it, ja, ko, nl, pl, pt, sv, uk, ru, zh.
- Links — 62 million community-contributed cross-references and owl:sameAs links to other linked data sets on the Linked Open Data (LOD) Cloud that allow to effectively find and retrieve further information from the largest, decentral, change-sensitive knowledge graph on earth that has formed around DBpedia since 2007.
- Community extensions — Community-contributed extensions such as additional ontologies and taxonomies.
Release Frequency & Schedule
Going forward, releases will be scheduled for the 15th of January, April, June and September (with +/- 5 days tolerance), and are named using the same date convention as the Wikipedia Dumps that served as the basis for the release. An example of the release timeline is shown below:
| December 6–8 | Dec 8–20 | Dec 20–Jan 15 | Jan 15–Feb 8 |
| Wikipedia dumps for June 1 become available on https://dumps.wikimedia.org/ | Download and extraction with DIEF | Post-processing and quality-control period | Linked Data and SPARQL endpoint deployment |
Data Freshness
Given the timeline above, the EN Wikipedia data of DBpedia Snapshot has a lag of 1-4 months. We recommend the following strategies to mitigate this:
- DBpedia Snapshot as a kernel for Linked Data: Following the Linked Data paradigm, we recommend using the Linked Data links to other knowledge graphs to retrieve high-quality and recent information. DBpedia’s network consists of the best knowledge engineers in the world, working together, using linked data principles to build a high-quality, open, decentralized knowledge graph network around DBpedia. Freshness and change-sensitivity are two of the greatest data-related challenges of our time, and can only be overcome by linking data across data sources. The “Big Data” approach of copying data into a central warehouse is inevitably challenged by issues such as co-evolution and scalability.
- DBpedia Live: Wikipedia is unmistakenly the richest, most recent body of human knowledge and source of news in the world. DBpedia Live is just minutes behind edits on Wikipedia, which means that as soon as any of the 120k Wikipedia editors press the “save” button, DBpedia Live will extract fresh data and update. DBpedia Live is currently in tech preview status and we are working towards a high-available and reliable business API with support. DBpedia Live consists of the DBpedia Live Sync API (for syncing into any kind of on-site databases), Linked Data and SPARQL endpoint.
- Latest-Core is a dynamically updating Databus Collection. Our automated extraction robot “MARVIN” publishes monthly dev versions of the full extraction, which are then refined and enriched to become Snapshot.
Data Quality & Richness
We would like to acknowledge the excellent work of Wikipedia editors (~46k active editors for EN Wikipedia), who are ultimately responsible for collecting information in Wikipedia’s infoboxes, which are refined by DBpedia’s extraction into our knowledge graphs. Wikipedia’s infoboxes are steadily growing each month and according to our measurements grow by 150% every three years. EN Wikipedia’s inboxes even doubled in this timeframe. This richness of knowledge drives the DBpedia Snapshot knowledge graph and is further potentiated by synergies with linked data cross-references. Statistics are given below.
Data Access & Interaction Options
Linked Data
Linked Data is a principled approach to publishing RDF data on the Web that enables interlinking data between different data sources, courtesy of the built-in power of Hyperlinks as unique Entity Identifiers.
HTML pages comprising Hyperlinks that confirm to Linked Data Principles is one of the methods of interacting with data provided by the DBpedia Snapshot, be it manually via the web browser or programmatically using REST interaction patterns via https://dbpedia.org/resource/{entity-label} pattern. Naturally, we encourage Linked Data interactions, while also expecting user-agents to honor the cache-control HTTP response header for massive crawl operations. Instructions for accessing Linked Data, available in 10 formats.
SPARQL Endpoint
This service enables some astonishing queries against Knowledge Graphs derived from Wikipedia content. The Query Services Endpoint that makes this possible is identified by http://dbpedia.org/sparql, and it currently handles 7.2 million queries daily on average. See powerful queries and instructions (incl. rates and limitations).
An effective Usage Pattern is to filter a relevant subset of entity descriptions for your use case via SPARQL and then combine with the power of Linked Data by looking up (or de-referencing) data via owl:sameAs property links en route to retrieving specific and recent data from across other Knowledge Graphs across the massive Linked Open Data Cloud.
Additionally, DBpedia Snapshot dumps and additional data from the complete collection of datasets derived from Wikipedia are provided by the DBpedia Databus for use in your own SPARQL-accessible Knowledge Graphs.
DBpedia Ontology
This Snapshot Release was built with DBpedia Ontology (DBO) version: https://databus.dbpedia.org/ontologies/dbpedia.org/ontology–DEV/2021.11.08-124002 We thank all DBpedians for the contribution to the ontology and the mappings. See documentation and visualizations, class tree and properties, wiki.
DBpedia Snapshot Statistics
Overview. Overall the current Snapshot Release contains more than 850 million facts (triples).
At its core, the DBpedia ontology is the heart of DBpedia. Our community is continuously contributing to the DBpedia ontology schema and the DBpedia infobox-to-ontology mappings by actively using the DBpedia Mappings Wiki.
The current Snapshot Release utilizes a total of 55 thousand properties, whereas 1377 of these are defined by the DBpedia ontology.
Classes. Knowledge in Wikipedia is constantly growing at a rapid pace. We use the DBpedia Ontology Classes to measure the growth: Total number in this release (in brackets we give: a) growth to the previous release, which can be negative temporarily and b) growth compared to Snapshot 2016-10):
- Persons: 1768613 (1.02%, 1.11%)
- Places: 745010 (1.01%, 1812.68%), including but not limited to 588283 (1.01%, 5497.97%) populated places
- Works 607852 (1.01%, 617.11%), including, but not limited to
- 157266 (1.00%, 1.38%) music albums
- 143193 (1.01%, 15.80%) films
- 24658 (1.01%, 12.44%) video games
- Organizations: 343109 (1.01%, 108.54%), including but not limited to
- 86950 (1.01%, 2.23%) companies
- 64539 (1.00%, 64539.00%) educational institutions
- Species: 1918094 (11.95%, 319682.33%)
- Plants: 9369 (0.89%, 2.07%)
- Diseases: 10553 (1.00%, 8.51%)
Detailed Growth of Classes: The image below shows the detailed growth for one class. Click on the links for other classes: Place, PopulatedPlace, Work, Album, Film, VideoGame, Organisation, Company, EducationalInstitution, Species, Plant, Disease. For further classes adapt the query by replacing the<http://dbpedia.org/ontology/CLASS> URI. Note, that 2018 was a development phase with some failed extractions. The stats were generated with the Databus VOID Mod.
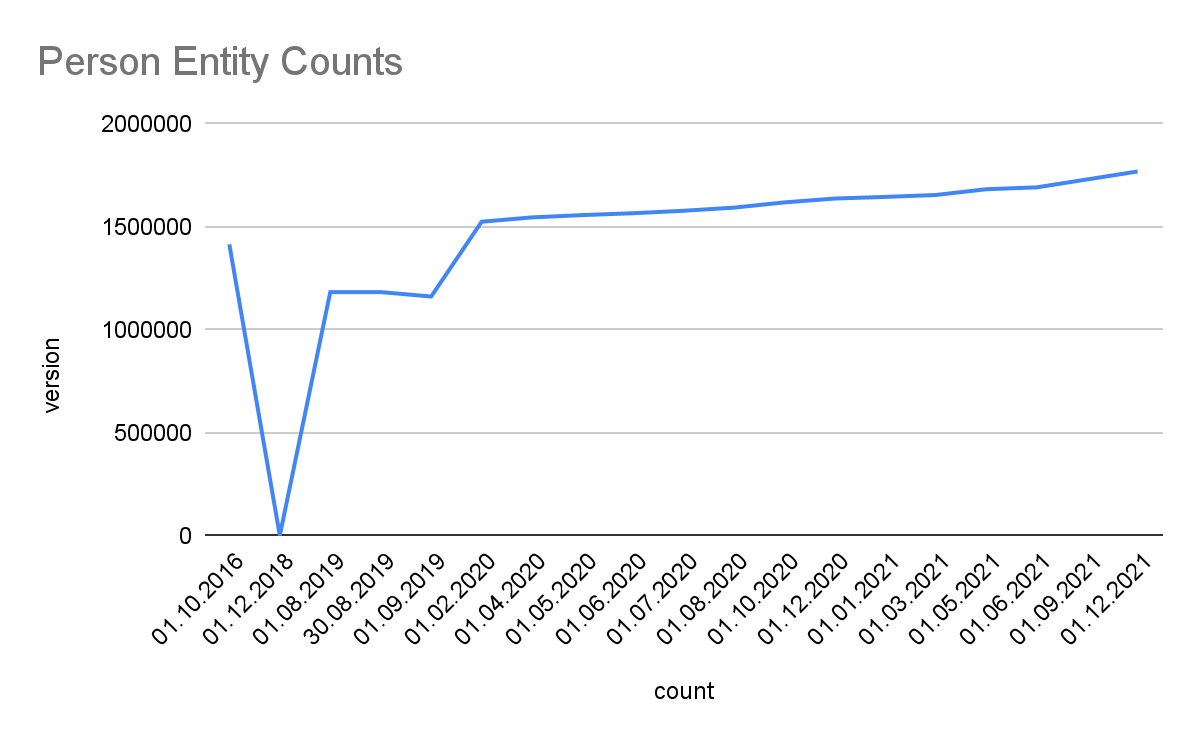
Links. Linked Data cross-references between decentral datasets are the foundation and access point to the Linked Data Web. The latest Snapshot Release provides over 129.9 million links from 7.54 million entities to 179 external sources.
Top 11
###TOP11###
33,522,731 http://www.wikidata.org
6,924,866 https://global.dbpedia.org
4,308,772 http://yago-knowledge.org
3,742,122 http://de.dbpedia.org
3,617,112 http://fr.dbpedia.org
3,067,339 http://viaf.org
2,860,142 http://it.dbpedia.org
2,841,468 http://es.dbpedia.org
2,609,236 http://fa.dbpedia.org
2,549,967 http://sr.dbpedia.org
2,496,247 http://ru.dbpedia.org
Top 10 without DBpedia namespaces
###TOP10###
33,522,731 http://www.wikidata.org
4,308,772 http://yago-knowledge.org
3,067,339 http://viaf.org
1,831,098 http://d-nb.info
641,602 http://sws.geonames.org
596,134 http://umbel.org
524,267 http://data.bibliotheken.nl
430,839 http://www.w3.org
370,844 http://musicbrainz.org
106,498 http://linkedgeodata.org
DBpedia Extraction Dumps on the Databus
All extracted files are reachable via the DBpedia account on the Databus. The Databus has two main structures:
- In groups, artifacts, version, similar to software in Maven: https://databus.dbpedia.org/$user/$group/$artifact/$version/$filename
- In Databus collections that are SPARQL queries over https://databus.dbpedia.org/yasui filtering and selecting files from these artifacts.
Snapshot Download. For downloading DBpedia Snapshot, we prepared this collection, which also includes detailed releases notes: https://databus.dbpedia.org/dbpedia/collections/dbpedia-snapshot-2021-12
The collection is roughly equivalent to http://downloads.dbpedia.org/2016-10/core/.
Collections can be downloaded in many different ways, some download modalities such as bash script, SPARQL, and plain URL list are found in the tabs at the collection. Files are provided as bzip2 compressed n-triples files. In case you need a different format or compression, you can also use the “Download-As” function of the Databus Client (GitHub), e.g. –s $collection -c gzip would download the collection and convert it to GZIP during download.
Replicating DBpedia Snapshot on your server can be done via Docker, see https://hub.docker.com/r/dbpedia/virtuoso-sparql-endpoint-quickstart.
git clone https://github.com/dbpedia/virtuoso-sparql-endpoint-quickstart.git
cd virtuoso-sparql-endpoint-quickstart
COLLECTION_URI=https://databus.dbpedia.org/dbpedia/collections/dbpedia-snapshot-2021-12 VIRTUOSO_ADMIN_PASSWD=password docker-compose up
Download files from the whole DBpedia extraction. The whole extraction consists of approx. 20 Billion triples and 5000 files created from 140 languages of Wikipedia, Commons and Wikidata. They can be found in https://databus.dbpedia.org/dbpedia/(generic|mappings|text|wikidata)
You can copy-edit a collection and create your own customized (e.g.) collections via “Actions” -> “Copy Edit” , e.g. you can Copy Edit the snapshot collection above, remove some files that you do not need and add files from other languages. Please see the Rhizomer use case: Best way to download specific parts of DBpedia. Of course, this only refers to the archived dumps on the Databus for users who want to bulk download and deploy into their own infrastructure. Linked Data and SPARQL allow for filtering the content using a small data pattern.
Acknowledgments
First and foremost, we would like to thank our open community of knowledge engineers for finding & fixing bugs and for supporting us by writing data tests. We would also like to acknowledge the DBpedia Association members for constantly innovating the areas of knowledge graphs and linked data and pushing the DBpedia initiative with their know-how and advice.
OpenLink Software supports DBpedia by hosting SPARQL and Linked Data; University Mannheim, the German National Library of Science and Technology (TIB) and the Computer Center of University Leipzig provide persistent backups and servers for extracting data. We thank Marvin Hofer and Mykola Medynskyi for technical preparation. This work was partially supported by grants from the Federal Ministry for Economic Affairs and Energy of Germany (BMWi) for the LOD-GEOSS Project (03EI1005E), as well as for the PLASS Project (01MD19003D).
- Did you consider this information as helpful?
- Yep!Not quite ...