DBpedia Member Features – In the coming weeks we will give DBpedia members the chance to present special products, tools and applications and share them with the community. We will publish several posts in which DBpedia members provide unique insights. Ontotext will start with the GraphDB database. Have fun while reading!
by Milen Yankulov from Ontotext
GraphDB is a family of highly efficient, robust, and scalable RDF databases. It streamlines the load and use of linked data cloud datasets, as well as your own resources. For easy use and compatibility with the industry standards, GraphDB implements the RDF4J framework interfaces, the W3C SPARQL Protocol specification, and supports all RDF serialization formats. The database offers open source API and it is the preferred choice of both small independent developers and big enterprise organizations because of its community and commercial support, as well as excellent enterprise features such as cluster support and integration with external high-performance search applications – Lucene, Solr, and Elasticsearch. GraphDB is build 100% on Java in order to be OS Platform independent.
GraphDB is one of the few triplestores that can perform semantic inferencing at scale, allowing users to derive new semantic facts from existing facts. It handles massive loads, queries, and inferencing in real-time.
GDB Architecture
GraphDB Workbench
Workbench is the GraphDB web-based administration tool. The user interface is similar to the RDF4J Workbench Web Application, but with more functionality.
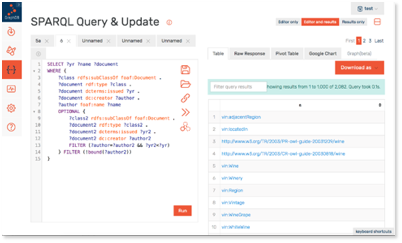
GraphDB Engine
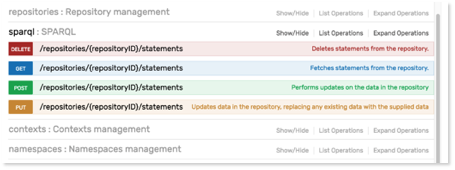
The GraphDB Workbench REST API can be used for managing locations and repositories programmatically, as well as managing a GraphDB cluster. It includes connecting to remote GraphDB instances (locations), activating a location, and different ways for creating a repository.
It includes also connecting workers to masters, connecting masters to each other, as well monitoring the state of a cluster.
GraphQL access via Ontotext Platform 3
GraphDB enables Knowledge Graph access and updates via GraphQL. GraphDB is extended to support the efficient processing of GraphQL queries and mutations to avoid the N+1 translation of nested objects to SPARQL queries.

Ontotext offers three editions of GraphDB: Free, Standard, and Enterprise.
Free – commercial, file-based, sameAs & query optimizations, scales to tens of billions of RDF statements on a single server with a limit of two concurrent queries.
Standard Edition (SE) – commercial, file-based, sameAs & query optimizations, scales to tens of billions of RDF statements on a single server and an unlimited number of concurrent queries.
Enterprise Edition (EE) – high-availability cluster with worker and master database implementation for resilience and high-performance parallel query answering.
Why GraphDB is preferred choice of many data architects and data ops?
3 Reasons:
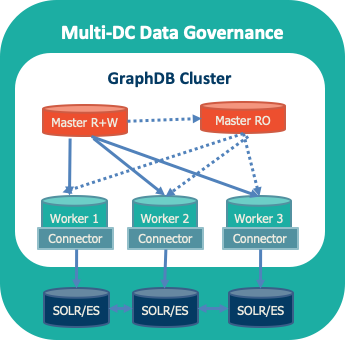
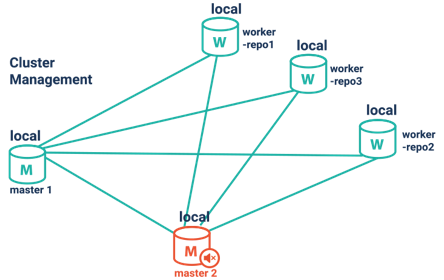
1. High Availability Cluster Architecture
GraphDB offers you a high-performance cluster proven to scale in production environments. It supports
- (1) coordinating all read and write operations,
- (2) ensuring that all worker nodes are synchronized,
- (3) propagating updates (insert and delete tasks) across all workers and checking updates for inconsistencies,
- (4) load balancing read requests between all available worker nodes
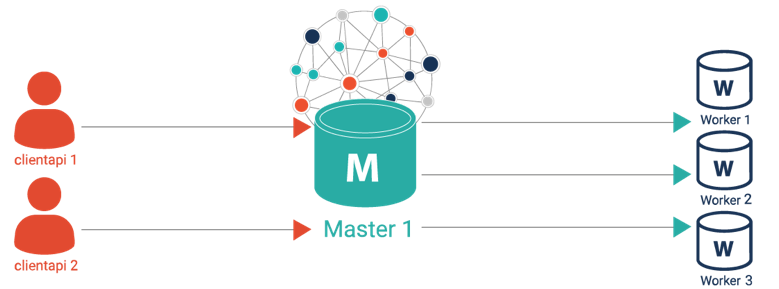
Improved resilience
failover, dynamic configuration
Improved query bandwidth
larger cluster means more queries per unit time
Deployable across multiple data centres
Elastic scaling in cloud environments
Integration with search engines
Cluster Management and Monitoring
It supports
(1) automatic cluster reconfiguration in the event of failure of one or more worker nodes,
(2) a smart client supporting multiple endpoints.
2. Easy Setup
GraphDB is 100% Java based in order to be Platform Independent. It is available through Native Installation Packages or Open Maven. It supports also Puppet and could be Dockerized. GraphDB is Cloud agnostic – It could be deployd on AWS, Azure, Google Cloud, etc.
3. Support
Based on the Edition you are using you could use the Community Support (StackOverFlow monitoring)
Ontotext has its Dedicated Support Team tha could assist through Customized Runbooks, Easy Slack communication, Jira Issue-Tracking System
A big thank you to Ontotext for providing some insights into their product and database.
Yours,
DBpedia Association
- Did you consider this information as helpful?
- Yep!Not quite ...