RDF2NL is featured in the following guest post by Diego Moussalem, (Dice Research Group & Portuguese DBpedia Chapter).
Hi DBpedians,
During the DBpedia Day in Leipzig, I gave a talk about how to use the facts contained in the DBpedia Knowledge Graph for generating coherent sentences and texts.
We essentially rely on Natural Language Generation (NLG) techniques for accomplishing this task. NLG is the process of generating coherent natural language text from non-linguistic data (Reiter and Dale, 2000). Despite community agreement on the actual text and speech output of these systems, there is far less consensus on what the input should be (Gatt and Krahmer, 2017). A large number of inputs have been taken for NLG systems, including images (Xu et al., 2015), numeric data (Gkatzia et al., 2014), semantic representations (Theune et al., 2001).
Why not generate text from Knowledge graphs?
The generation of natural language from the Semantic Web has been already introduced some years ago (Ngonga Ngomo et al., 2013; Bouayad-Agha et al., 2014; Staykova, 2014). However, it has gained recently substantial attention and some challenges have been proposed to investigate the quality of automatically generated texts from RDF (Colin et al., 2016). Moreover, RDF has demonstrated a promising ability to support the creation of NLG benchmarks (Gardent et al., 2017). Still, English is the only language which has been widely targeted. Thus, we proposed RDF2NL which can generate texts in other languages than English by relying on different language versions of SimpleNLG.
What is RDF2NL?
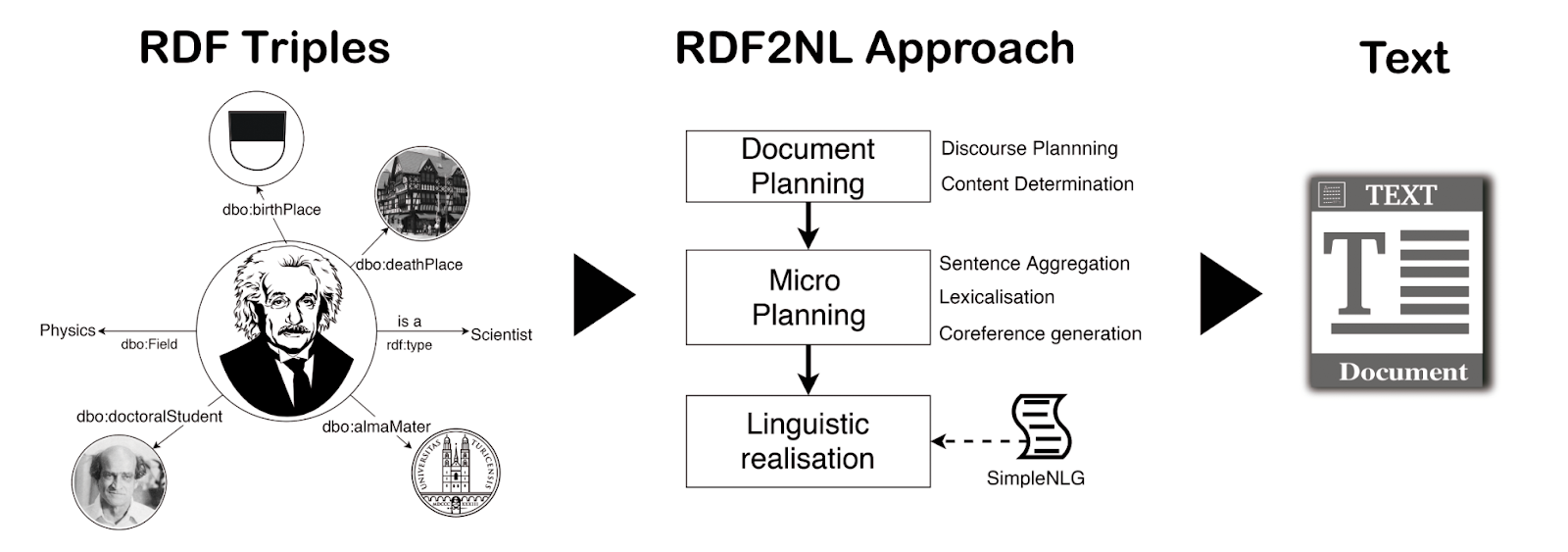
While the exciting avenue of using deep learning techniques in NLG approaches (Gatt and Krahmer, 2017) is open to this task and deep learning has already shown promising results for RDF data (Sleimi and Gardent, 2016), the morphological richness of some languages led us to develop a rule-based approach. This was to ensure that we could identify the challenges imposed by each language from the SW perspective before applying Machine Learning (ML) algorithms. RDF2NL is able to generate either a single sentence or a summary of a given resource. RDF2NL is based on Ngonga Ngomo et.al LD2NL and it also uses the Brazilian, Spanish, French, German and Italian adaptations of SimpleNLG to the realization task.
An example of RDF2NL application:
We envisioned a promising application by using RDF2PT which aims to support the automatic creation of benchmarking datasets to Named Entity Recognition (NER) and Entity Linking (EL) tasks. In Brazilian Portuguese, there is a lack of gold standards datasets for these tasks, which makes the investigation of these problems difficult for the scientific community. Our aim was to create Brazilian Portuguese silver standard datasets which are able to be uploaded into GERBIL for easy evaluation. To this end, we implemented RDF2PT ( Portuguese version of RDF2NL) in BENGAL , which is an approach for automatically generating NER benchmarks based on RDF triples and Knowledge Graphs. This application has already resulted in promising datasets which we have used to investigate the capability of multilingual entity linking systems for recognizing and disambiguating entities in Brazilian Portuguese texts. Some results you can find below:
NER – http://gerbil.aksw.org/gerbil/experiment?id=201801050043
NED – http://gerbil.aksw.org/gerbil/experiment?id=201801110012
More application scenarios
- Summarize or Explain KBs to non-experts
- Create news automatically (automated journalism)
- Summarize medical records
- Generate technical manuals
- Support the training of other NLP tasks
- Generate product descriptions (Ebay)
Deep Learning into RDF2NL
After devising our rule-based approach, we realized that RD2NL is really good by selecting adequate content from the RDF triples, but the fluency of its generated texts remains a challenge. Therefore, we decided to move forward and work with neural network models to improve the fluency of texts as they have already shown promising results in the generation of translations. Thus, we focused on the generation of referring expressions, which is an essential part while generating texts, it basically decides how the NLG model will present the information about a given entity. For example, the referring expressions of the entity Barack Obama can be “the former president of USA”, “Obama”, “Barack”, “He” and so on. Afterward, we have been working on combining different NLG sub-tasks into single neural models for improving the fluency of our texts.
GSoC on it – Stay tuned!
Apart from trying to improve the fluency of our models, we relied previously on different language versions of SimpleNLG to the realization task. Nowadays, we have been investigating the generation of multiple languages by using a unique neural model. Our student has been working hard to provide nice results and we are basically at the end of our GSoC project. So stay tuned to know the outcome of this exciting project.
Many thanks to Diego for his contribution. If you want to write a guest post, share your results on the DBpedia Blog, and thus give your work more visibility and outreach, just ping us via dbpedia@infai.org.
Yours
DBpedia Association
- Did you consider this information as helpful?
- Yep!Not quite ...