We are thrilled to announce that our Databus Collection Feature for the DBpedia Databus has been developed and is now available as a prototype. It simplifies the way to bundle your data and use it in your application.
A new Databus Collection Feature? How come, and how does it work? Read below and find out how using the DBpedia Databus becomes easier by the day and with each new tool.
Motivation
With more and more data being uploaded to the databus we started to develop test applications using that data. The SPARQL endpoint offers a central hub to access all metadata for datasets uploaded to the databus provided you know how to write SPARQL queries. The metadata includes the download links of the data files – it was, therefore, possible to pass a SPARQL query to an application, download the actual data and then use for whatever purpose the app had.
The Databus Collection Editor
The DBpedia Databus now provides an editor for collections. A collection is basically a labelled SPARQL query that is retrievable via URI. Hence, with the collection editor you can group Databus groups and artifacts into a bundle and publish your selection using your Databus account. It is now a breeze to select the data you need, share the exact selection with others and/or use it in existing or self-made applications.
If you are not familiar with SPARQL and data queries, you can think of the feature as a shopping cart for data: You create a new cart, put data in it and tell your friends or applications where to find it. Quite neat, right?
In the following section, we will cover the user interface of the collection editor.
The Editor UI
Firstly, you can find the collection editor by going to the DBpedia Databus and following the Collections link at the top or you can get there directly by clicking here.
What you will see is the following:
General Collection Info
Secondly, since you do not have any collections yet, the editor has already created an empty collection named “Unnamed” for you. At the right side next to the label and description you will find a pen icon. By clicking the icon or the label itself you can edit its content. The collection is not published yet, so the Collection URI is blank.
Whenever you are not logged in or the collection has not been published yet, the editor will also notify you that your changes are only saved in your local browser cache and NOT remotely on our server. Keep that in mind when clearing your cache. Publishing the collection however is easy: Simply log into (or create) your Databus account and hit the publish button in the action bar. This will open up a modal where you can pick your unique collection id and hit publish again. That’s it!
The Collection Info section will now show the collection URI. Following the link will take you to the HTML representation of your collection that will be visible to others. Hitting the Edit button in the action bar will bring you back to the editor.
Collection Hierarchy
Let’s have a look at the core piece of the collection editor: the hierarchy view. A collection can be a bundle of different Databus groups and artifacts but is not limited to that. If you know how to write a SPARQL query, you can easily extend your collection with more powerful selections. Therefore, the hierarchy is split into two nodes:
- Generated Queries: Contains all queries that are generated from your selection in the UI
- Custom Queries: Contains all custom written SPARQL queries
Both, hierarchy nodes have a “+” icon. Clicking on this button will let you add generated or custom queries respectively.
Custom Queries
If you hit the “+” icon on the Custom Queries node, a new node called “Custom Query” will appear in the hierarchy. You can remove a custom query by clicking on the trashcan icon in the hierarchy. If you click the node it will take you to a SPARQL input field where you can edit the query.
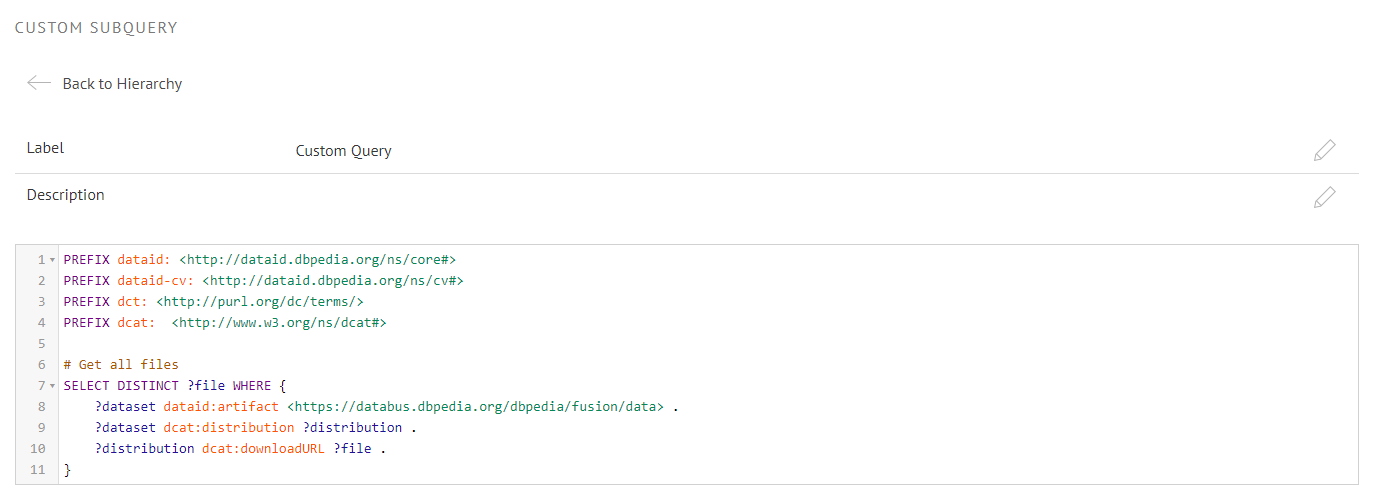
To make your collection more understandable for others, you can even document the query by adding a label and description.
Writing Your Own Custom Queries
A collection query is a SPARQL query of the form:
SELECT DISTINCT ?file WHERE {
{
[SUBQUERY]
}
UNION
{
[SUBQUERY]
}
UNION
...
UNION
{
[SUBQUERY]
}
}All selections made by generated and custom queries will be joined into a single result set with a single column called “file“. Thus it is important that your custom query binds data to a variable called “file” as well.
Generated Queries
Clicking the “+” icon on the Generated Queries node will take you to a search field. Make use of the indexed search on the Databus to find and add the groups and artifacts you need. If you want to refine your search, don’t worry: you can do that in the next step!
Once the artifact or group has been added to your collection, the Add to Collection button will turn green. Once you are done you can go back to the Editor with Back to Hierarchy button.
Your hierarchy will now contain several new nodes.
Group Facets, Artifact Facets and Overrides
Group and artifacts that have been added to the collection will show up as nodes in the hierarchy. Clicking a node will open a filter where you can refine your dataset selection. Setting a filter to a group node will apply it to all artifact nodes unless you override that setting in any artifact node manually. The filter set in the group node is shown in the artifact facets in dark grey. Any overrides in the artifact facets will be highlighted in green:
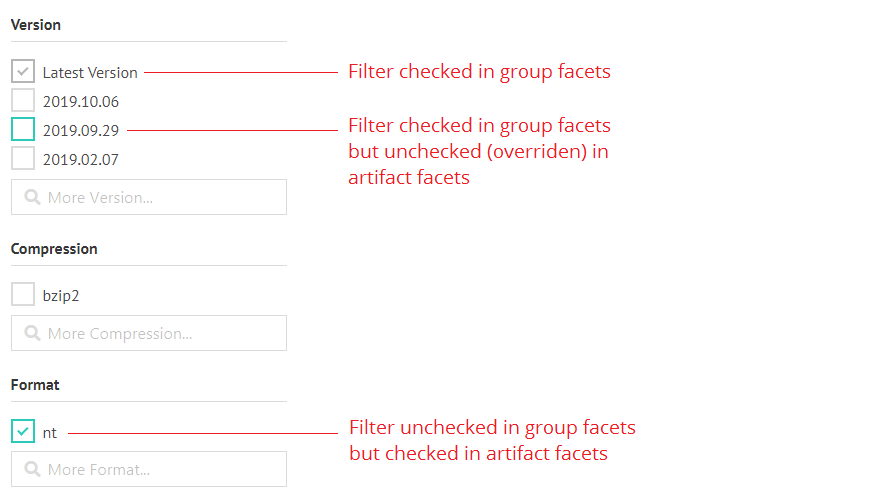
Group Nodes
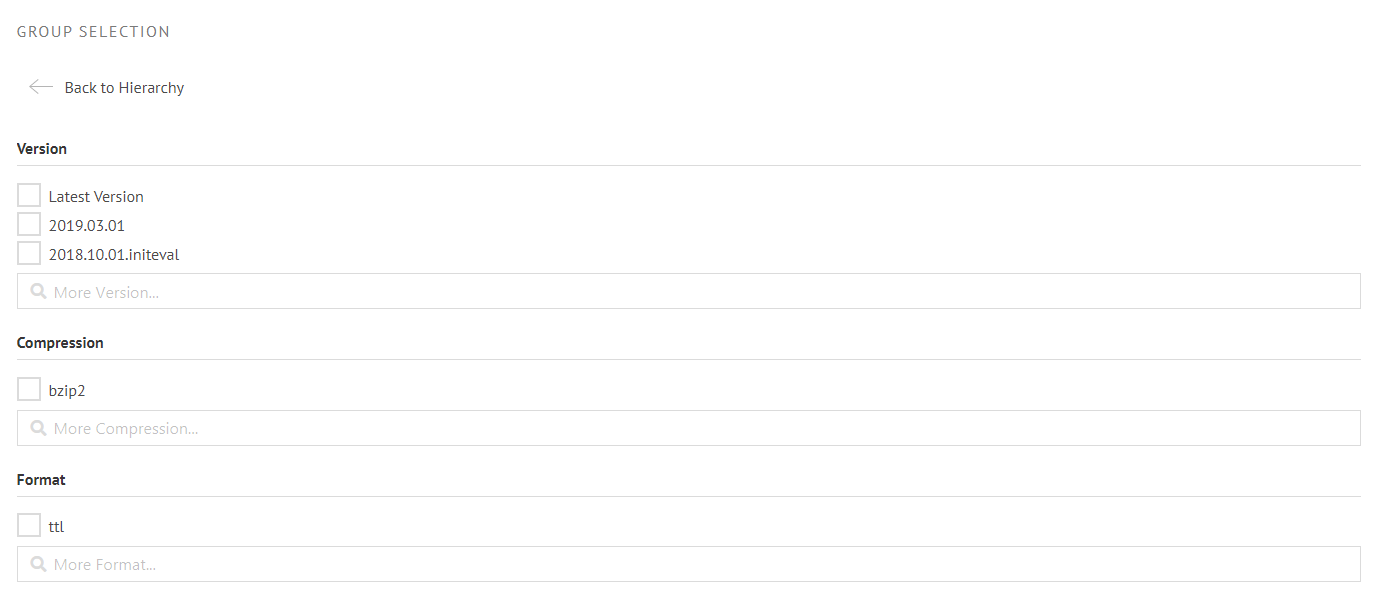
A group node will provide a list of filters that will be applied to all artifacts of that group:
Artifact Nodes
Artifact nodes will then actually select data files which will be visible in the faceted view. The facets are generated dynamically from the available variants declared in the metadata.
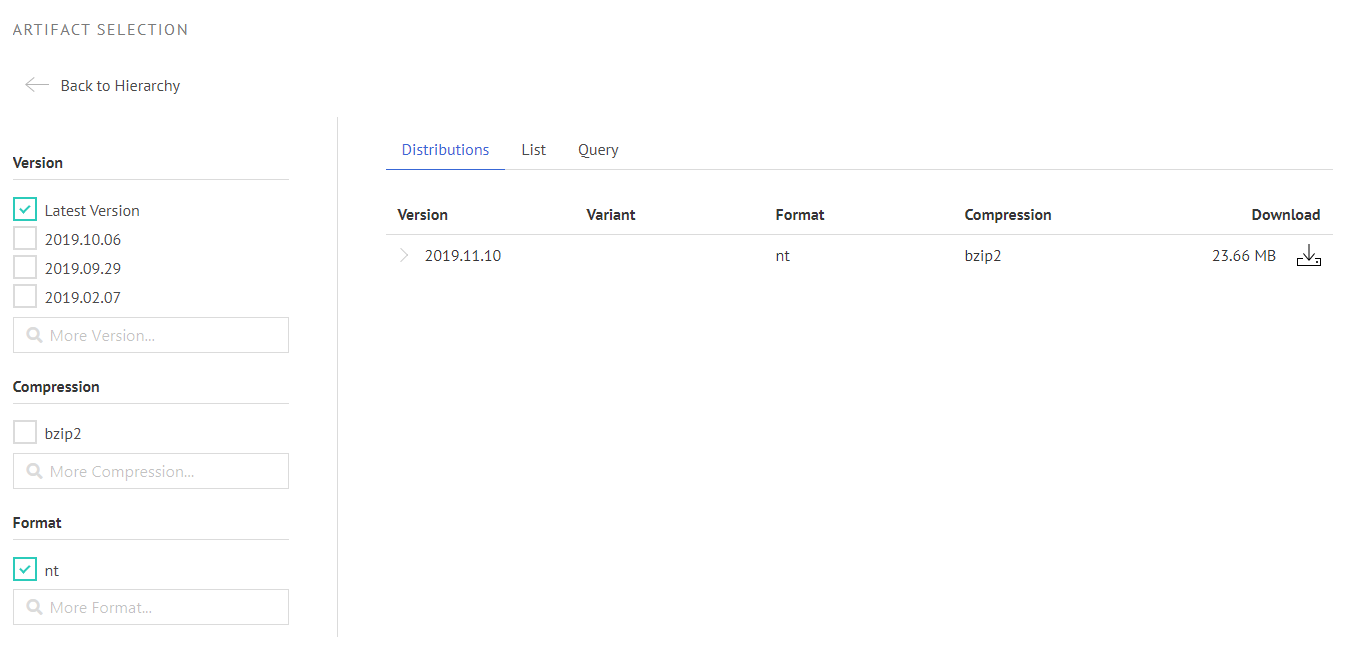
Example: Here we selected the latest version of the databus dump as n-triple. This collection is already in use: The collection URI is passed to the new generic lookup application, which then creates the search function for the databus website. If you are interested in how to configure the lookup application, you can go here: https://github.com/dbpedia/lookup-application. Additionally, there will also be another blog post about the lookup within the next few weeks
Use Cases
The DBpedia Databus Collections are useful in many ways.
- You can share a specific dataset with your community or colleagues.
- You can re-use dataset others created
- You can plug collections into databus-ready applications and avoid spending time on the download and setup process
- You can point to a specific piece of data (e.g. for testing) with a single URI in your publications
- You can help others to create data queries more easily
We hope you enjoy the Databus Collection Feature and we would love to hear your feedback! You can leave your thoughts and suggestions in the new DBpedia Forum. Feedback of any kinds is highly appreciated since we want to improve the prototype as fast and user-driven as possible! Cheers!
A big thanks goes to DBpedia developer Jan Forberg who finalized the Databus Collection Feature and compiled this text.
Yours
DBpedia Association
- Did you consider this information as helpful?
- Yep!Not quite ...